-20250819-084018.svg)
The Issue Types Health Checks category includes the following checks:
-
Duplicate issue types
-
Inactive issue types
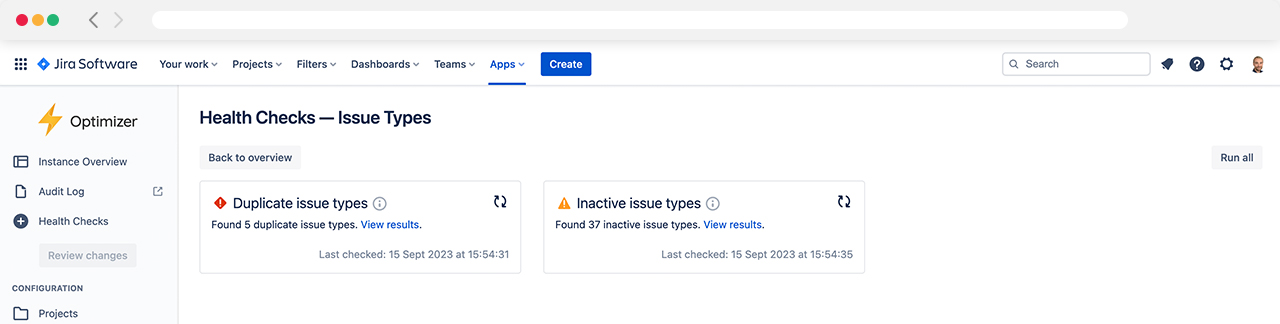
Available Health Checks for Issue Types
Duplicate issue types
The ‘Duplicate issue types’ health check detects issue types with identical or very similar names. There are many customisation options available, allowing you to control the rules used to determine whether issue types should be considered duplicates.
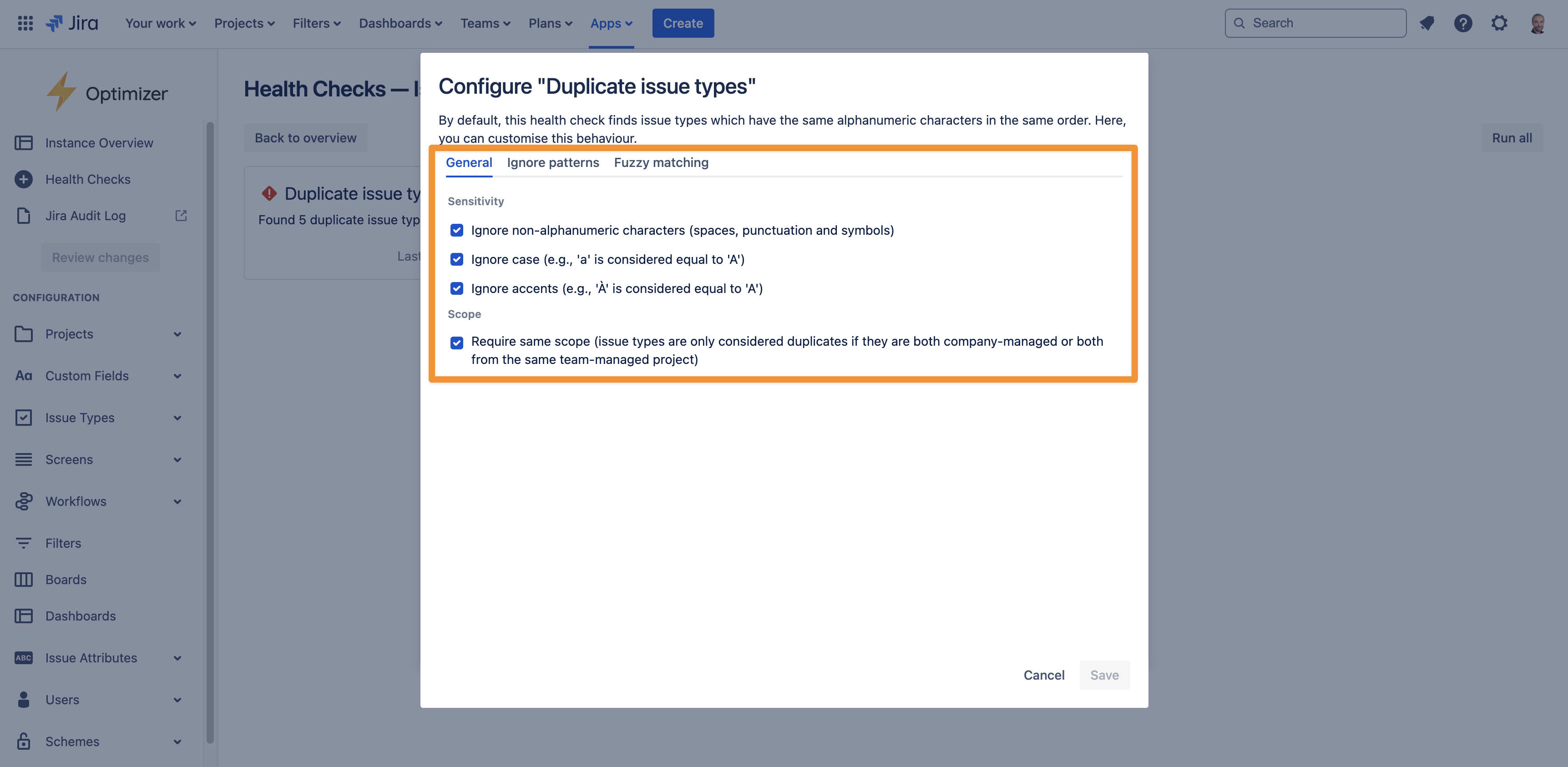
Select the sensitivity
-
Ignore non-alphanumeric characters: when this option is active, characters such as punctuation, spaces, and symbols will be ignored when comparing issue types. For example, issue types with names “Subtask“ and “Sub-task“ will be considered equivalent
-
Ignore case: with this option active, issue types whose names differ only in the casing will be considered duplicates, e.g., “Feature Request“ and “Feature Request.”
-
Ignore accents: if this option is active, then issue types with names differing only in accents/diacritics will be identified as duplicates, such as “Role“ and “Rôle.“
Ignore patterns
These allow you to specify custom pieces of text to be ignored when checking whether two issue types are duplicates. Each pattern can be included as a prefix, suffix, or both. For example, if you add a suffix ignore pattern of “(migrated)” then the duplicate issue types health check will mark the issue types “Expense” and “Expense (migrated)” as duplicates.
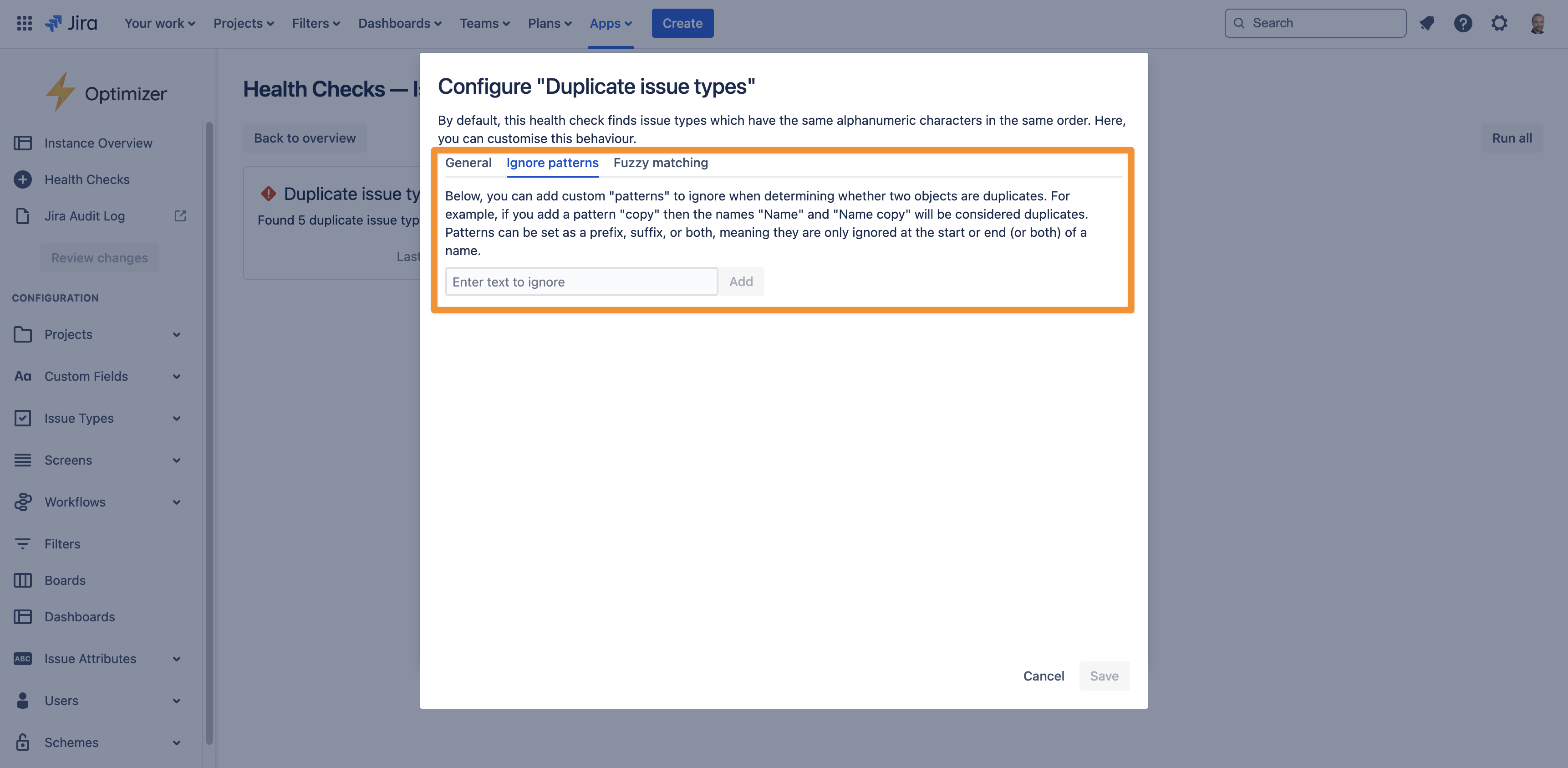
This can be especially helpful if you have used the Jira Cloud Migration Assistant to migrate your instance from Jira on-premise to Jira Cloud since it can introduce many such duplicate objects.
Fuzzy matching
By default, the duplicate issue types check uses a “strict” searching strategy to find results. This means it won’t pick up on issue types which are slightly different but likely duplicates, for example due to a typo, such as “Initiative” and “Intiative”.
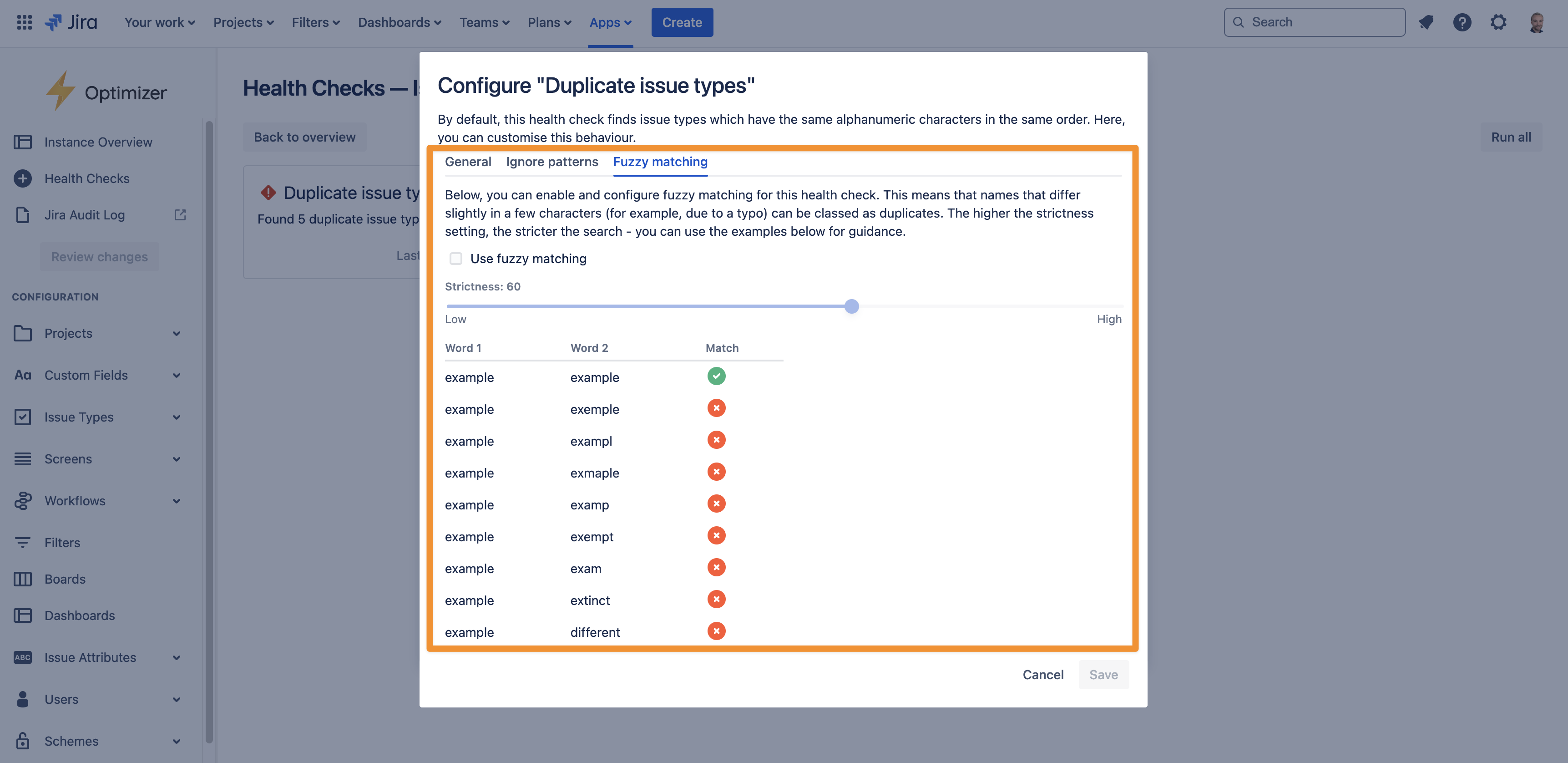
For this reason, a more flexible searching strategy is available in the ‘Fuzzy matching’ tab. There, you can choose a threshold that determines how similar the names of two issue types must be to be considered duplicates: the higher the threshold, the closer the match must be. The image below shows some examples.
Inactive issue types
The ‘Inactive issue types’ health check scans for issue types that are used for few issues. By default, this includes issue types used on at most 5 issues, but this can be set to any value as shown in the image below.
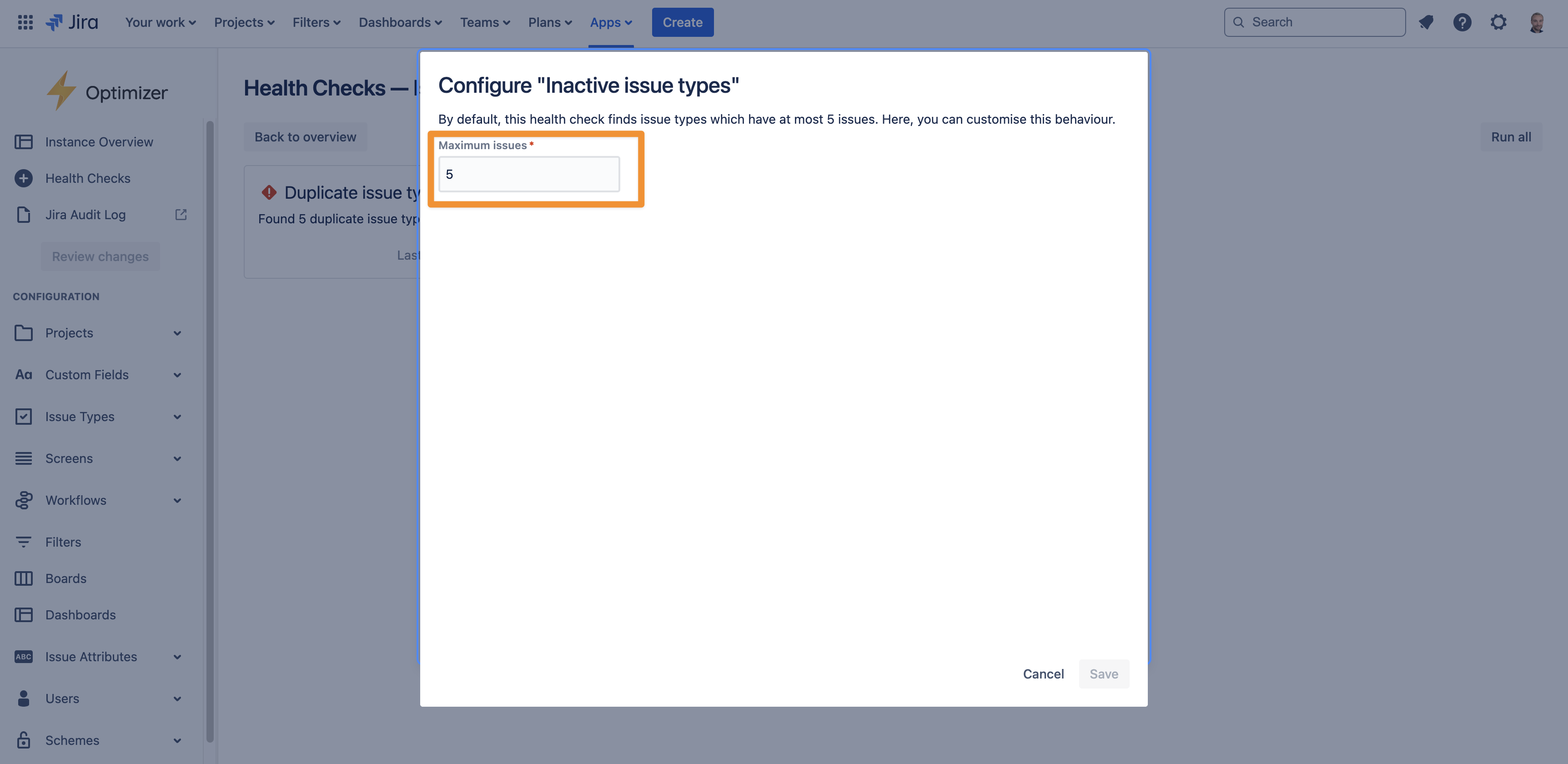
For example, setting the maximum issues to 0 will mean only unused issues are detected, but note that an issue security scheme could still prevent usages of an issue type from being visible.
Viewing and actioning results
Clicking the ‘results' link will open a popup showing a summary of the duplicate issue types found in your instance, as shown in the image below.
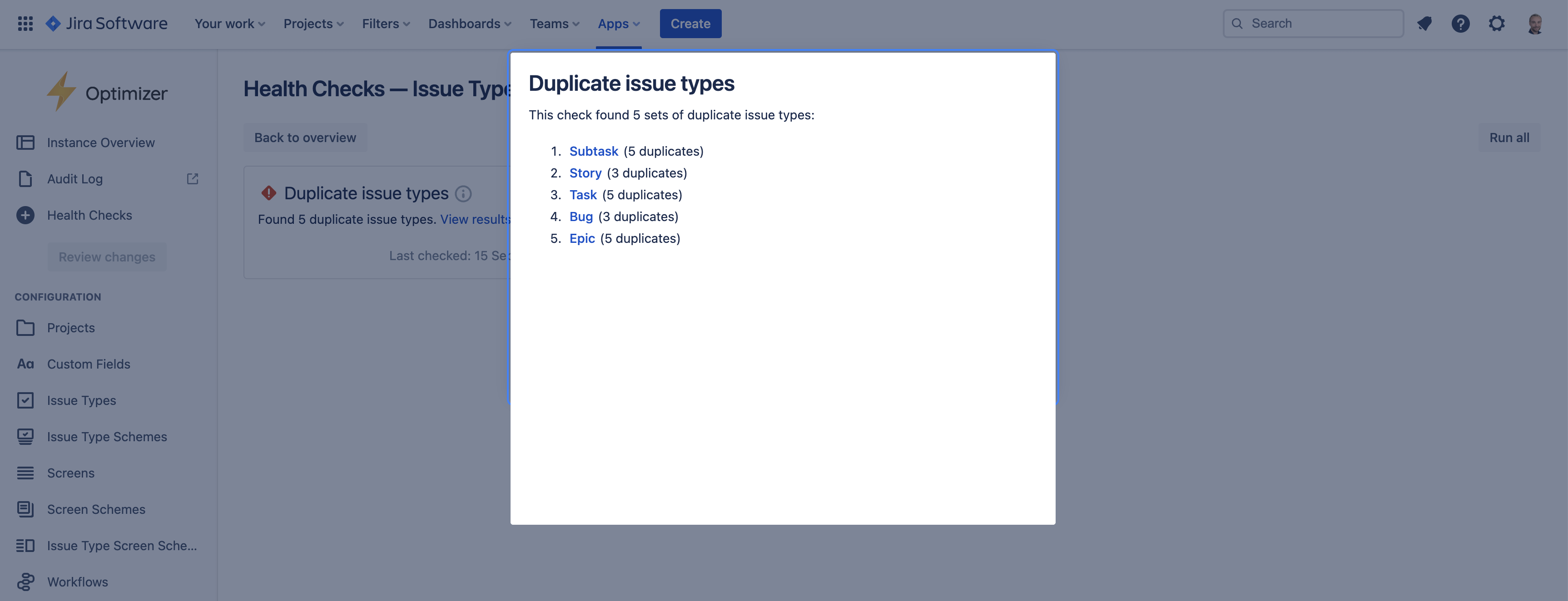
From the summary popup, clicking on one of the links will take you to a smart table showing the full set of duplicates.
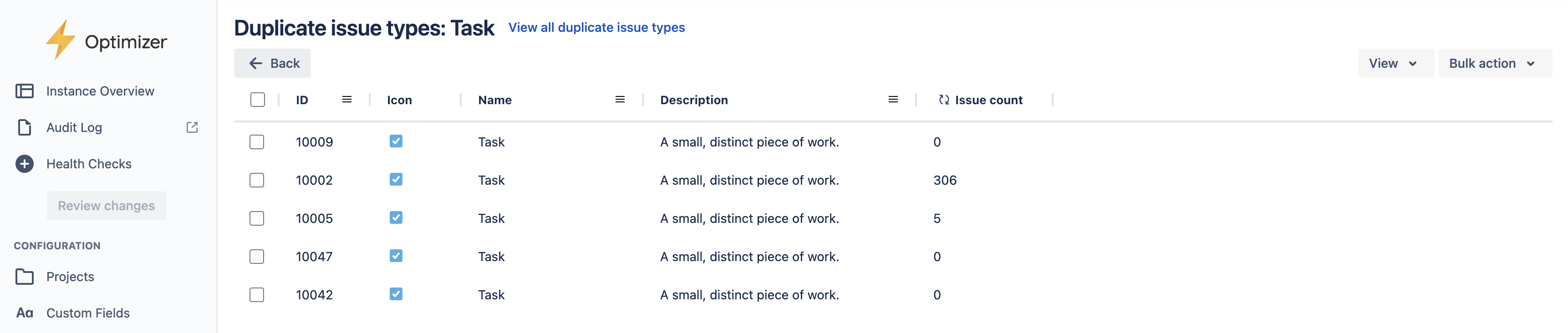
The smart table allows you to perform actions such as deleting duplicates if they are unused and changing the name and description of issue types to clarify their usage.
You can quickly access the summary popup from the smart table by clicking the ‘Overview’ link at the top of the page.
Need support? We’re here to help 🧡
If you have any questions about Optimizer or would like to speak with us, please don’t hesitate to contact our Customer Support team.