%20v2.png)
Enable Sensitive Data Detection
With the increase in Information Security standards, through ISO 27001 or the IASME Governance Standards, Sensitive Data that is on pages needs to be handled in the appropriate manner.
Compliance for Confluence allows for the automatic detection of sensitive data in Confluence. This data is predefined by our system extractions or we allow the creation of custom extractions.
There are a number of steps required to enable this feature, which will determine:
What is scanned for (e.g. Email Addresses, Phone Numbers)
Where is scanned (e.g. particular Spaces)
When a scan will take place (on page operation and/or scheduled)
Pro Tip: It's recommended that you configure the extractions, scope and automation rules before you run any scans. This helps to prevent the need to re-scan the instance.
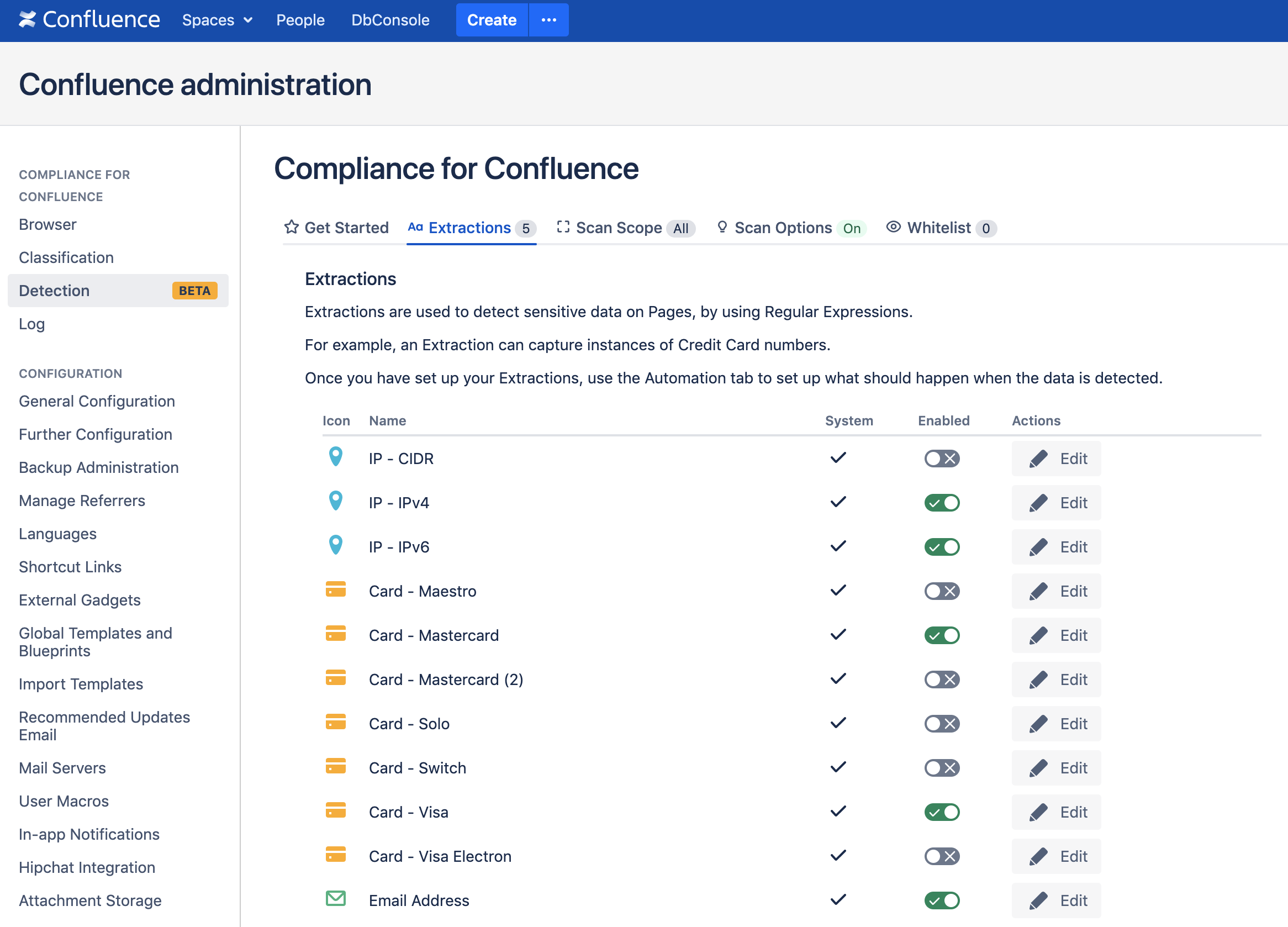
Extractions
The first thing to configure is the extractions, these are the patterns which documents are scanned for.
An example of an extraction might be as follows:
Name | IP - IPv4 |
|---|---|
Description | Internet Protocol address (IP address) is a numerical label assigned to each device connected to a computer network. |
Icon | Address |
Pattern |
|
Enabled | true |
As you can see, it describes a particular type of sensitive data which we want to detect.
Extractions are either:
System-provided
Manually created
Please Note: Before Extractions are searched for during analysis, they must first be enabled.
How To Enable Sensitive Data Extraction
Navigate to: Settings > Compliance Configuration > Detection > Extractions
Find an extraction that suits your needs from a selection of pre-defined extractions and enable it using the toggle OR create a new extraction by clicking "Add Extraction" at the bottom of the page
In the dialog, create a name, description and select an icon for your new extraction. In the extraction box, add a regular expression that captures the sensitive information. This will be validated against Java RE/2
Click Create
Find your new extraction in the list and enable it using the toggle